SEFCOM Research Internship
This summer I had decided to attend a high school research internship at the SEFCOM lab with Zion Basque also known as mahaloz serving as my mentor. Within this post I will document my work and findings throughout the course of the internship, as well as various insights I have acquired as a result.
My work throughout the course of the internship was largely centered around implementing simplifcation passes with the goal of improving readability. I had implemented it within the angr decompiler.
Background
As a bit of background, decompilation1 is the process of lifting and simplifying low level code into higher level constructs. This allows a human to more efficiently analyze such abstractions which serves to aid in the process of static binary analysis and source code recovery.
In the directed and lossy process of compilation, information is invariably lost as a result such as type information, comments, preprocessor directives (inlined and expanded before compilation), symbol names (when stripped) and more.
Aggressive optimizations are known to potentially mutate the original structure and control flow of the program into an entirely separate CFG, yet still manage to preserve the same semantic properties as the original, making decompilation more difficult2.
This can lead to less accurate decompilation output due to the fact that structuring relies heavily on the accuracy of Control Flow Recovery.
The decompilation process generally follows a similar pipeline documented below.
- Lifting Phase
- The first step of the decompilation phase involves the disassembly and conversion of low level code into an intermediate representation (IR) which generally preserves the semantics of the original program.
- As a result of this lifting phase, the decompilation engine can be portable by operating on our intermediate representation as opposed to each and every single architecture we decide we want to support.
- Control Flow Analysis3
- This next process within the decompilation pipeline concerns itself with control flow graph recovery. This phase generally serves to construct basic blocks from the lifted intermediate representation and attaching directed edges to represent control flow.
- Within the recovered control flow graph, basic blocks represent vertices and edges represent control flow within the program.
- This step within the decompilation process is crucial as any discrepancies can lead to drastic alterations within the resulting output. There are various algorithms for control flow graph recovery which is known to work well in practice.
- Variable and Type Analysis
- The next step involves itself with recovering vital information of the variables within our program. Within a relatively high level language, types represent sets of values which serve to impose semantic constraints on symbolic values or expressions. However at a low level, the microprocessor is only concerned with the size and sign of a variable.
- Variable Analysis and Recovery is generally done by assigning symbols to regions of memory which may potentially represent variables within the program. Such variables can include memory addresses, registers and et cetera.
- The process of Type Analysis and Recovery is generally done via a technique known as Value Set Analysis (VSA). This process utilizes the various operations and statements performed on recovered variables to impose semantic constraints. This process is fully documented within the paper, TIE: Principled Reverse Engineering of Types in Binary Programs4.
- Something to keep in mind is the fact that a symbolic or value can potentially represent different types at different locations within the CFG. The process of value set analysis is to deduce the set of all potential types which it can represent.
- Control Flow Structuring is the process of identifying and converting CFG sections into linear code (usually in the form of C).
- In the field of Control Flow Structuring, there are really only two approaches: pattern and condition based matching, approached by Phoenix5 and Dream6 respectively.
- The last stage in the decompilation pipeline concerns itself with actually converting our recovered intermediate representation into C style source code (or whichever high level language we are targeting).
- Additional optimizations and simplification passes are also performed at this stage to improve the recovered source code.
Structured C Code Formatting
My first tasks generally revolved improving the structured C code generation by implementing simplification passes which served to refactor the output to adopt a more C-style format. The features I had implemented are cstyle_ifs and cstyle_nullcmp, both of which serve to reformat the resulting structured C code.
Each of these reformatting don’t actually affect structuring decisions, below is an example of both features.
int main(void) {
if (x == 0) {
return 1;
}
return 0;
}
This code is fine, but we can also represent it in a semantically equivalent form as follows which follows a more C-style format.
int main(void) {
if (!x)
return 1;
return 0;
}
We can see that it converts the condition to utilize the unary negation operator and removes the braces in the presence of a single statement. Each are fairly simple aesthetic adjustments, but it makes the resulting decompilation look much more readable in my opinion.
Control Flow Structuring
The next feature I had implemented concerns itself with simplification of the decompilations control flow structure with the goal of reducing complexity and improving structural similarity with the original source.
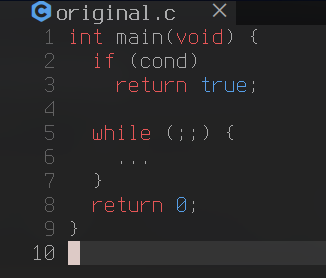
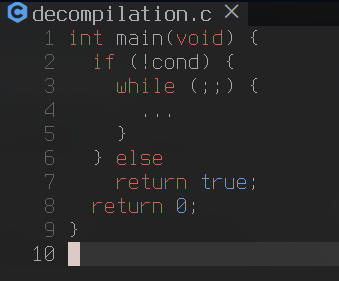
There are a few semantically sound means of structuring a CFG, each with varying tradeoffs, consider the following example.
| Original Source CFG | Decompilation CFG |
|---|---|
 |  |
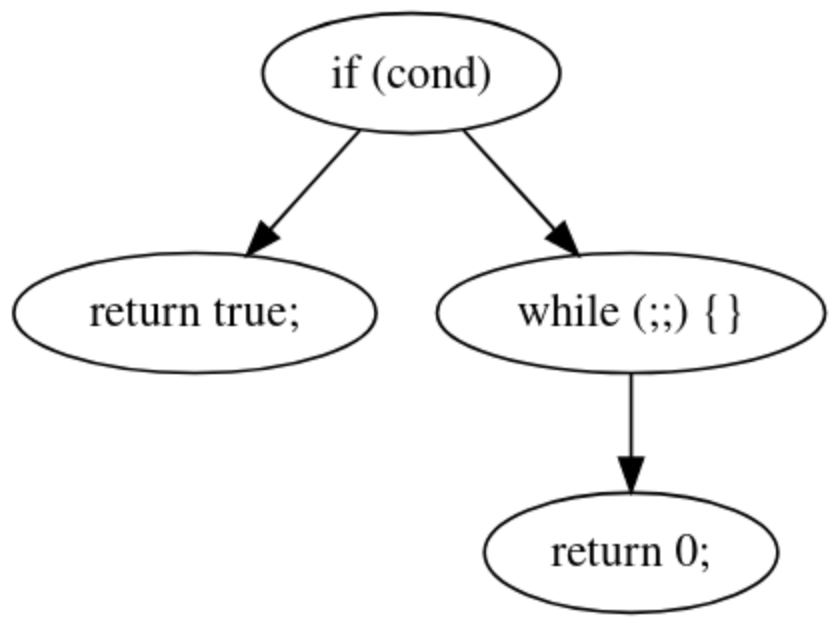 | 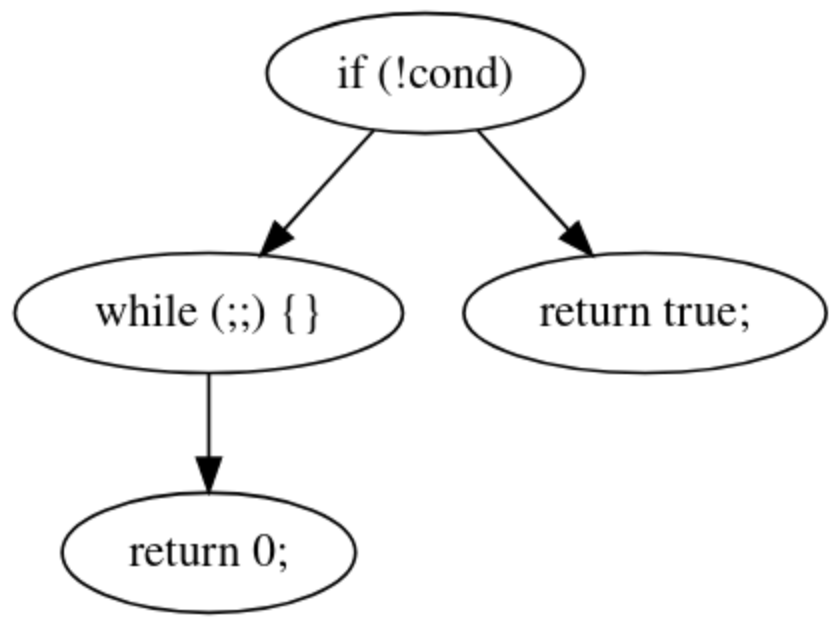 |
Both CFGs are technically semantically equivalent, however the original source is an objectively better way of structuring this case as it reduces the quantity of scopes, thereby reducing complexity.
This is what my feature attempts to mediate and in doing so allows the resulting structured C code generation to resemble the original source. So how is this optimization implemented and how does it work?
First and foremost, we can identify this case by checking whether or not the false branch contains any successors. By doing so we can identify if the branch exits from the procedure.
Lets use the following example as a means of demonstrating the process in which the optimization pass takes.
Original decompilation output
int main(int argc, char** argv) {
if (argc)
putchar('a');
else
return 1;
return 0;
}
The optimization flips the true and false branches of the condition node and negates the condition within the comparison iff the else branch does not contain any successors.
int main(int argc, char** argv) {
if (!argc)
return 1;
else
putchar('a');
return 0;
}
Now due to the fact that the
truebranch does not return, it will never fall through so theelsestatement is redundant. Due to this property we can completely remove the else branch.
int main(int argc, char** argv) {
if (!argc)
return 1;
putchar('a');
return 0;
}
My optimization pass implements this simplification at scale, quantitatively decreasing the complexity of the decompilation and increasing the structural similarity with the original source.
Metrics
The example provided is very minute, however when analyzing large binaries, such a feature scales by reducing complexity of the resulting decompilation and in turn saving the reverse engineer time and cognitive load.
We can utilize two relevant metrics for evaluating the impact of this feature.
- The total sum of instances in which the feature triggers.
- The quantity of scopes present within decompilation.
We can measure the first quantitative metric by instrumenting the feature within angr and
running against the coreutils test suite, this feature was triggered a cumulative total of
496 times.
The next metric can be evaluated by comparing the results of the angr decompiler with that of Binary Ninja’s and Hexray’s commercially licensed decompilers. The results were attained by putting each decompiler up against the coreutils test suite and measuring the quantity of scopes present within the decompilation.
| Original Source | Binary Ninja | HexRays Decompiler | Angr (enabled) | Angr (disabled) |
|---|---|---|---|---|
| 7259 | 19513 | 11820 | 14821 | 14960 |
In total, we beat Binary Ninja in this metric by a total margin of 4692 scopes, which is more accurate to the original source code of the coreutils test suite. There were 139 unique instances in which the optimization was able to remove a redundant else scope.
We can also measure accuracy of our decompilation by comparing between Angr and Binary Ninja’s decompilers with the original source to measure correctness.
Original reformatted source of
od.o:skip
static bool skip(uintmax_t n_skip) {
bool ok = true;
int in_errno = 0;
if (n_skip == 0)
return true;
while (in_stream != NULL)
{
struct stat file_stats;
if (fstat(fileno(in_stream), &file_stats) == 0) {
bool usable_size = usable_st_size(&file_stats);
if (usable_size && ST_BLKSIZE(file_stats) < file_stats.st_size) {
if ((uintmax_t)file_stats.st_size < n_skip)
n_skip -= file_stats.st_size;
else {
if (fseeko(in_stream, n_skip, SEEK_CUR) != 0) {
in_errno = errno;
ok = false;
}
n_skip = 0;
}
}
else if (!usable_size && fseeko(in_stream, n_skip, SEEK_CUR) == 0)
n_skip = 0;
else {
char buf[BUFSIZ];
size_t n_bytes_read, n_bytes_to_read = BUFSIZ;
while (0 < n_skip) {
if (n_skip < n_bytes_to_read) n_bytes_to_read = n_skip;
n_bytes_read = fread(buf, 1, n_bytes_to_read, in_stream);
n_skip -= n_bytes_read;
if (n_bytes_read != n_bytes_to_read) {
if (ferror(in_stream)) {
in_errno = errno;
ok = false;
n_skip = 0;
break;
}
if (feof(in_stream))
break;
}
}
}
if (n_skip == 0)
break;
}
else {
error(0, errno, "%s", quotef(input_filename));
ok = false;
}
ok &= check_and_close(in_errno);
ok &= open_next_file();
}
if (n_skip != 0)
die(EXIT_FAILURE, 0, _("cannot skip past end of combined input"));
return ok;
}
Binary Ninja Decompilation of
od.o:skip
uint64_t skip(int64_t arg1)
{
int64_t var_1028;
int64_t var_1028_1 = var_1028;
int64_t var_2028;
int64_t var_2028_1 = var_2028;
void* fsbase;
int64_t rax = *(int64_t*)((char*)fsbase + 0x28);
int64_t rbp_1;
int32_t r12_1;
if (arg1 != 0)
{
rbp_1 = arg1;
int32_t r13_1 = 0;
r12_1 = 1;
while (true)
{
uint64_t r14_2 = in_stream;
if (r14_2 == 0)
{
break;
}
void var_20c8;
if (fstat(((uint64_t)fileno(r14_2)), &var_20c8) != 0)
{
int64_t rax_14 = quotearg_n_style_colon(0, 3, input_filename);
r12_1 = 0;
error(0, ((uint64_t)*(int32_t*)__errno_location()), &.LC40, rax_14);
}
else
{
int32_t var_20b0;
char rax_13 = usable_st_size.isra.0(var_20b0);
int64_t var_2098;
int64_t rdx_3;
if (rax_13 != 0)
{
rdx_3 = 0x200;
int64_t var_2090;
if ((var_2090 - 1) <= 0x1fffffffffffffff)
{
rdx_3 = var_2090;
}
if (var_2098 > rdx_3)
{
if (var_2098 < rbp_1)
{
rbp_1 = (rbp_1 - var_2098);
}
else if (rpl_fseeko(r14_2, rbp_1, 1) == 0)
{
rbp_1 = 0;
}
else
{
r12_1 = 0;
rbp_1 = 0;
r13_1 = *(int32_t*)__errno_location();
}
}
}
if ((rax_13 == 0 || (rax_13 != 0 && var_2098 <= rdx_3)))
{
int32_t rax_4;
if (rax_13 == 0)
{
rax_4 = rpl_fseeko(r14_2, rbp_1, 1);
if (rax_4 == 0)
{
rbp_1 = 0;
}
}
if ((rax_13 != 0 || (rax_13 == 0 && rax_4 != 0)))
{
int64_t rbx_1 = 0x2000;
while (rbp_1 != 0)
{
if (rbx_1 > rbp_1)
{
rbx_1 = rbp_1;
}
void var_2038;
int64_t rax_5 =
__fread_unlocked_chk(&var_2038, 0x2000, 1, rbx_1, in_stream);
rbp_1 = (rbp_1 - rax_5);
if (rbx_1 != rax_5)
{
uint64_t r14_1 = in_stream;
if (ferror_unlocked(r14_1) != 0)
{
r12_1 = 0;
rbp_1 = 0;
r13_1 = *(int32_t*)__errno_location();
break;
}
if (feof_unlocked(r14_1) != 0)
{
break;
}
}
}
}
}
if (rbp_1 == 0)
{
break;
}
}
r12_1 = ((r12_1 & check_and_close(r13_1)) & open_next_file());
}
if (rbp_1 != 0)
{
error(1, 0, dcgettext(0, "cannot skip past end of combined…", 5));
}
}
if (((arg1 != 0 && rbp_1 != 0) || arg1 == 0))
{
r12_1 = 1;
}
if (rax != *(int64_t*)((char*)fsbase + 0x28))
{
__stack_chk_fail();
/* no return */
}
return ((uint64_t)r12_1);
}
Angr Decompilation of
od.o:skip
extern char in_stream;
extern char input_filename;
int skip(unsigned long long a0)
{
char v0; // [bp-0x20c8]
char v1; // [bp-0x20b0]
unsigned long long v2; // [bp-0x2098]
unsigned long v3; // [bp-0x2090]
char v4; // [bp-0x2038]
unsigned long v5; // [bp-0x2028]
unsigned long v6; // [bp-0x1028]
void* v8; // rbp
void* v9; // r13, Other Possible Types: unsigned long long
unsigned long long v10; // rax
unsigned long long v11; // rcx
unsigned long long v12; // rbx
unsigned long long v13; // rax
unsigned long v14; // r12, Other Possible Types: void*
unsigned long long v15; // rax
v6 = v6;
v5 = v5;
if (!a0)
{
return 1;
}
v8 = a0;
v9 = 0;
v14 = 1;
while (true)
{
if (!in_stream)
break;
if (fstat(fileno(in_stream), &v0))
{
v14 = quotearg_n_style_colon(0x0, 0x3, input_filename);
*((unsigned int *)&v14) = 0;
error(0x0, *(__errno_location()), "%s");
}
else
{
(char)v10 = usable_st_size.isra.0(*((int *)&v1));
if (!(char)v10 ||
(v11 = v2, v2 <= (v3 - 1 <= 2305843009213693951? v3 : 0x200)))
{
if ((char)v10 || rpl_fseeko(in_stream, v8, 0x1))
{
v12 = 0x2000;
while (true)
{
if (!v8)
break;
v12 = (!(v12 <= v8)? v8 : v12);
v13 = __fread_unlocked_chk(&v4, 0x2000, 0x1, v12, in_stream);
v8 -= v13;
if (v12 == v13)
continue;
if (ferror_unlocked(in_stream))
{
v14 = 0;
v8 = 0;
*((unsigned int *)&v9) = *(__errno_location());
break;
}
else if (feof_unlocked(in_stream))
{
break;
}
}
}
else
{
v8 = 0;
}
}
else
{
if (v11 < v8)
{
v8 -= v11;
}
else if (!rpl_fseeko(in_stream, v8, 0x1))
{
v8 = 0;
}
v14 = 0;
v8 = 0;
v9 = *(__errno_location());
}
if (!v8)
break;
}
(unsigned int)v15 = check_and_close((unsigned int)v9);
*((unsigned int *)&v14) = (unsigned int)v14 & (unsigned int)v15;
*((unsigned int *)&v14) = (unsigned int)v14 & open_next_file();
}
if (v8)
error(0x1, 0x0, dcgettext(NULL,
"cannot skip past end of combined input", 0x5));
return v14;
}
By comparing each side by side, we can see that the structuring of the angr decompiler now that the feature has been implemented largely resembles that of the source code. Thanks to the removal of the redundant else scope, we have decompilation which is much more correct and accurate.
The simplified_else optimizations implementation is contained with this merged pull request if you would like more details.
Conclusion
Lastly I want to thank my amazing mentor Zion as well as the people at SEFCOM for providing me the opportunity to study under their guidance.
Throughout the course of the internship I’ve been able to learn a great deal about the field of decompilation, as well as enabling me to work on the internals angr.
Thanks for reading! (´▽`)